TOXIC COMMENT IDENTIFICATION
ABSTRACT:-
With the advancement of web technology and its growth, there is a huge volume of data present on the web for internet users and a lot of data is generated too. The Internet has become a platform for online learning, exchanging ideas and sharing opinions. Social networking sites like Twitter, Facebook, Google+ are rapidly gaining quality as they allow individuals to share and categorical their views regarding topics, have discussions with totally different communities, or post messages across the world . It is a speedily increasing service with over 200 million registered users out of that 100 million are active users and half of them go online twitter on each day to day – generating nearly 250 million tweets per day. Due to this huge quantity of usage we tend to hope to understand a reflection of public sentiment by analyzing the emotions expressed within the tweets. There has been a ton of work within the sector of sentiment analysis of twitter information.
This survey focuses within the main on sentiment analysis of twitter information that’s useful to research the knowledge within the tweets wherever opinions are extremely unstructured, heterogeneous and are either positive or negative, or neutral in some cases.In this paper, we provide a survey and comparative analyses of existing techniques for opinion mining like machine learning and lexicon-based approaches, together with evaluation metrics. Using various machine learning algorithms like Naive Bayes, Max Entropy, and Support Vector Machine, we provide research on twitter data streams. We have also discussed general challenges and applications of Sentiment Analysis on Twitter. The aim of this project is to develop a functional classifier for accurate and automatic sentiment classification of an unknown tweet stream.
OBJECTIVES OF THE PROJECT:-
The goal is to train a classifier model that can predict whether the input text is inappropriate (toxic).
- Explore the dataset to solicit a better picture of how labels are distributed, regardless of how they relate to each other and what defines toxic or clean comments.
- produce a base score with a simple regression classifier it provides.
- Explore the effectiveness of several machine learning approaches and choose the simplest for this problem.
- Choose the simplest model and adjust the parameters to maximize performance.
- Build the final model with the simplest algorithm and read parameters and examine a set of control information.
EXISTING SYSTEM:-
In the existing system People have built extensive models to express their thoughts through various devices. Not only has the internet become a believable way to express your thoughts, it is fast becoming the greatest medium for doing so. User behavior such as threats, poisonous comments, profanity, insults and abuse. The task of identifying and eliminating toxic communication in public forums is essential. Analyzing a large corpus of comments is not feasible for human moderators. Our approach is to use Natural Language Processing (NLP) techniques to provide an efficient and accurate tool for online toxicity detection. They apply the TFIDF feature extraction technique, a machine learning approach that includes a decision tree classifier with TF IDF and a keyword feature generation technique for the classification of comment toxicity, achieving an average precision of 91.64% The author can then apply the raster search algorithm on the same dataset on machine learning algorithms.
LIMITATIONS OF EXISTING SYSTEM :-
- A lot of search results that corresponding to a user’s query is not relevant to the user need
- It is time consuming because search result is irrelevant so not fulfill the users need.
- There are not reviews analysis only get reviews from user.
PROPOSED SYSTEM:-
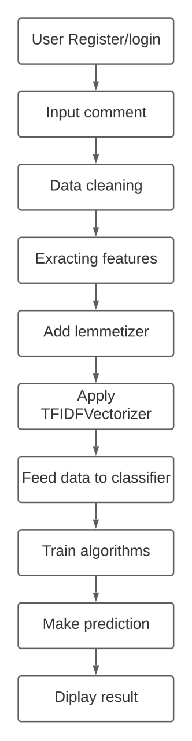
As a natural language processing problem, it is a classification task involving high-dimensional data. We use the vectorization of the data and test several classification algorithms. I will vectorize the text data with the term frequency – document inverse frequency statistics (tfidf). not only takes into account the frequency of words or character ngrams in the text, but also the relevance of these tokens in the entire data set -Ngrams will be a parameter to get higher performance later. We have also created a number of technical characteristics that contain various attributes of the comment text, such as: B. Average word length, capitalization and number of exclamation marks. We run the benchmark without these functions and experiment with them to optimize the solution. Using vectorization and benchmarking functions, we experiment with several algorithms with standard parameters to determine the most effective approach to the problem. The models we use are:
- Multinomial Naive Bayes
- Support Vector Machine
- Decision Tree
- Random Forest
Algorithm approaches can be too resource intensive for an algorithm that needs to be executed immediately every time a comment is posted on one of the most popular websites on the internet . If this were a real business problem, it is efficiency. Furthermore, fitting the model to secondary features would require stacking, which is a cluttered solution that increases the complexity of both training and prediction. It is much easier for third parties to analyze the impact of certain features on the model and make appropriate adjustments to combat bias. We predict that there will be confusion between Naive Bayes, Random Forest, Decision Tree and Support Vector Machines. good performance due to the large difference in vocabulary frequency distribution between comments. The Naive Bayes template fits the tf idf vectorized comment text using only words for the tokens, limited to 5,000 functions. The target value is any_label, but we also want to monitor the performance of the model on specific categories.
MODULES:
- User Register: User have to register to check whether product review is Toxic or not.
- User Login: User have to register to check whether product review is Toxic or not.
- Processing Sentence: Use Natural language processing (NLP) to makes possible for computers to read text, hear speech, interpret it, measure sentiment and determine which parts are important.
- Word to Vector: Tf-idf is used to transforming text into a numerical feature is called text vectorization which mathematically eliminates naturally occurring words in the English language, and selects words that are more descriptive of your text.
- Classifying Sentence: Based on Tf-idf vectors machine learning algorithms (SVM, Naive bayes, Random Forest, Decision tree) will classifying text.
ADVANTAGES:-
- Sentiment analysis gives a proper result of Toxic and non-toxic comments.
- Using this analysis we can easily get what is our system plus point and which sector require changes.
- Gives better services for user.
HARDWARE AND SOFTWARE REQUIREMENTS:-
HARDWARE:
- Processor: i5
- RAM: 4GB or more
- Hard disk: 16 GB or more
SOFTWARE SPECIFICATION:-
- Windows Operating System.
- jupyter
- spyder
- Anaconda
MySQL