VEHICLE ACCIDENT DETECTION
ABSTRACT:-
Every year, about 1.35 million humans are reduce off due to severa crashes withinside the occasion of a street visitors coincidence. According to statistics, 20 to 50 million people are injured due to it. People lose their lives due to such street injuries. These conditions are the end result of a loss of coordination a number of the entities involved. In addition, failing to absolutely exercise the regulations and strategies to be accompanied amplifies the graph upwards. Risk elements consist of speeding, drinking, and driving, distracted driving, bad infrastructure, risky automobiles, breaching regulations, and lots of others. As a end result, a device this is preferably able to coordinating the various steps that must be performed for a rapid reaction on the coincidence vicinity is required. According to the research, such detection structures hire numerous technology including Deep Learning methodologies and system learning approaches, amongst others. All automobiles are protected with the aid of using those detection structures, and extra technology are being examined. This paper offers a top level view of the technology which might be connected to street injuries via automatic street traffic coincidence detection structures.
EXISTING SYSTEM:-
Trajectory Prediction. Extensive studies has investigated trajectory prediction, regularly posed as a sequence-to-sequence technology problem. Alahi et al. [5] introduce a Social LSTM for pedestrian trajectories and their interactions. The proposed social pooling technique is in addition advanced through Gupta et al. [6] to seize worldwide context in a Generative Adversarial Network (GAN). Social pooling is likewise applied to car trajectory prediction in Deo et al. [7] with multimodal maneuver conditions. Other paintings [8], [9] captures scene context facts the usage of interest mechanisms to help trajectory prediction. Lee et al. [10] contain Recurrent Neural Networks (RNNs) with conditional variational autoencoders (CVAEs) to generate multimodal predictions and select the fine through rating scores. While the above techniques are designed for third-individual perspectives from static cameras, current paintings has taken into consideration imaginative and prescient in first-individual (egocentric) movies that seize the natural subject of view of the individual or agent (e.g., car) wearing the digital digicam to take a look at the digital digicam wearer’s actions [11], [12], trajectories [13], interactions [14], [15], etc. Bhattacharyya et al. [16] are expecting destiny places of pedestrians from vehiclemounted cameras, modeling commentary uncertainties with a Bayesian LSTM community. Yagi et al. [17] contain special types of cues right into a convolution-deconvolution (Conv1D) community to are expecting pedestrians’ destiny places. Yao et al. [18] enlarge this paintings to self sufficient riding eventualities through offering a multi-movement RNN Encoder-Decoder (RNN-ED) structure with each beyond car places and photograph functions as inputs for waiting for car places. Video Anomaly Detection. Video anomaly detection has obtained giant interest in laptop imaginative and prescient and robotics [19]. Previous paintings especially specializes in video surveillance eventualities commonly the usage of an unmanaged gaining knowledge of technique at the reconstruction of ordinary schooling data. For example, Hasan et al. [20] advocate a three-D convolutional Auto-Encoder (Conv-AE) to version non-anomalous frames. To take benefit of temporal facts, [21], [22] use a Convolutional LSTM Auto-Encoder (ConvLSTM-AE) to seize normal visible and movement styles simultaneously. Luo et al. [23] advocate a unique framework of sRNN, known as temporally-coherent sparse coding (TSC), to preserve the similarities among frames inside ordinary and bizarre events. Liu et al. [3] discover anomalies through searching for variations among a expected destiny body and the actual body. However, in dynamic self sufficient riding eventualities, it is tough to reconstruct both the modern-day or destiny RGB frames because of the ego-vehicle’s excessive movement. It is even tougher to discover bizarre events. This paper proposes detecting injuries on roads through the usage of the distinction among expected and actual trajectories of different vehicles. Our technique now no longer best eliminates the computational fee of reconstructing complete RGB frames, however additionally localizes capability anomaly participants. Prior paintings has additionally detected anomalies along with moving violations and vehicle collisions on roads. Chan et al. [2] introduce a dataset of crowd-sourced dashcam movies and a dynamic-spatial-interest RNN version for twist of fate detection. Herzig et al. [24] advocate a Spatio-Temporal Action Graph (STAG) community to version the latent graph shape of spatial and temporal family members among gadgets. These techniques are primarily based totally on supervised gaining knowledge of that calls for laborious human annotations and makes the unrealistic assumption that all bizarre styles had been located withinside the schooling data. This paper considers the hard however sensible problem of predicting injuries with unsupervised gaining knowledge of. To examine our approach, we introduce a brand new dataset with traffic injuries concerning gadgets along with vehicles and pedestrians.
PROPOSED SYSTEM:-
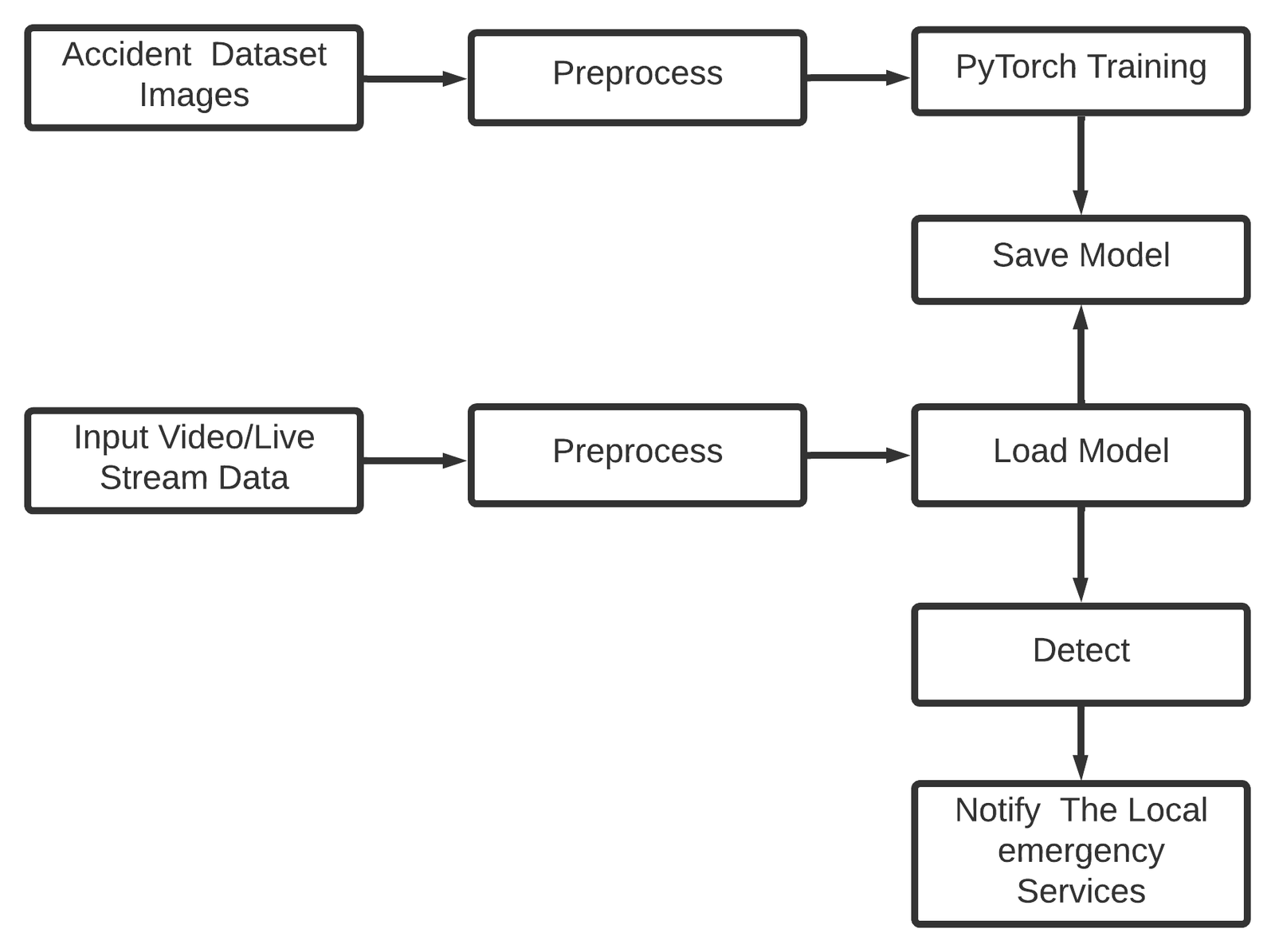
1.Data Collection:
Image facts units are used withinside the proposed solution. The first is made of pics that have been applied to fine-track the visible characteristic vector extractor. The picture dataset changed into comprised of scratch, the usage of the net scraping approach to populate it. A series of affordable moves changed into provided to perform this. First, we decided the web sites from which the image seek changed into conducted. The series of key phrases for the searches changed into then defined. The following key phrases have been selected for this process: Accidents involving traffic, automobiles, motorcycles, and vehicles The automation level changed into then completed. [3] The utility changed into created in Python the usage of the Selenium library, which incorporates beneficial capabilities for doing this operation. Finally, all of the received pics have been manually validated, at the side of an picture transformation, to standardize the length and layout used.
- Pre-processing:
A photo is segmented to generate a larger quantity of examples with a set quantity of photos and, as a result, a section with a shorter time. This is due to the fact visitors incidents have a brief average duration (10 frames), making an allowance for greater green processing of the unique video. Some experiments had been achieved at the dataset’s films in an effort to select out the segmentation method for the enter data. In each example, the techniques to be evaluated had been in comparison the use of the same films. [12] The first technique is a segmentation with out body discrimination. As a result, all next snap shots withinside the video are selected till the phase’s most time is achieved.
- Accident Detection & Notification:
The recommended method is primarily based totally on a visible and a temporal characteristic extractor. The PYTORCH structure is used withinside the version’s first step (pre-educated with the twist of fate dataset). That is, all the Inception cells (convolutional layers) had been utilized, ensuing withinside the removal of the multilayer perceptron on the cease of this design. This is to apply the higher segment of the version simply as a visible characteristic extractor. However, numerous trials found out that the pre-educated version does now no longer distinguish among a vehicle at relaxation and a automobile concerned in a visitors collision. [11] As a result, the pix dataset become used for training to fine-track the weights of this pre-educated network. During this procedure, all the weights of the structure’s preliminary layers had been frozen, and simplest the weights of PyTorch’s very last convolutional mobileular had been modified. Several trials had been achieved in an effort to fine-track the characteristic extractor. If the twist of fate become detected, then the device notifies the primary responders i.e., Local emergency services. Which in a roundabout way allows to lessen the reaction time and store the life. Because of distinction among short while or even seconds its costing a life. Because this device.
MODULES:-
- Image Capture Module:
Image capture is done by video capture devices like cameras and then saved in convenient formats like mp4, mkv, etc. OpenCV is the library used to access the video captured by the camera. Cv2 OpenCV library is used to capture the video and pass it frame by frame for further processing. - Vehicle Detection Module:
TensorFlow is the framework to create a deep learning network that solves object detection problems. There are models in your framework that are available through the reference as Model Zoo. This includes a collection of pre-trained models trained on the COCO dataset, the KITTI dataset, and the Open Images dataset. Here we use the COCO data set.
- Accident Detection:
The implementation of this system is divided into several modules. The system mainly consists of basic modules, the first is car accident detection, which is achieved by using any high-definition camera, such as CCTV, etc. and then we use PyTorch to detect crashes. The next module, vehicle detection and classification, was developed using Yolo. Our third module is Velocity Calculation, developed with OpenCV by manipulating and calculating image pixels. Object counting, the TensorFlow is used in this project as the basis for object counting. Finally, the warning system is activated when the vehicle exceeds a certain threshold.
ADVANTAGES OF THE PROJECT:-
- Automatic alert on crossing speed limit
- Immediate help can be provided
- Nearest hospitals can be located
- Accident rate can be reduced
- Parents monitor their child driving
HARDWARE AND SOFTWARE REQUIREMENTS
HARDWARE:
- Processor: Intel Core i3 or more.
- RAM: 4GB or more.
- Hard disk: 250 GB or more.
Software:
- Windows Operating System.
- flask , jupyter notebook ,spyder
- Python
- Anaconda