Abstractive Text Summarization Using LSTM AND RNN
ABSTRACT: –
Text summarisation has been one among the foremost well-known issues in natural language process and deep learning in recent years. A text summary usually contains a brief note on an oversized text document. Automatic text summary generation is the task of generating a brief summary for a comparatively long text document by capturing its key information. Within the past, supervised statistical machine learning has been widely used for the automated Text summarisation (ATS) task, however because of the high dependence on the standard of text components, the generated summaries lack accuracy and coherence, whereas the machine power and performance achieved couldn’t simply meet current wants. Our main goal is to make a brief, fluent and intelligible abstract summary of a text document. To make a good summary, we tend to use the amazon fine food reviews dataset accessible on Kaggle.
We used the textual descriptions of the reviews as input data and created an easy summary of those review descriptions because of the output. To assist in producing some broad summaries, we used a bidirectional RNN with an LSTM within the cryptography layer and an attention model within the decoding layer. We tend to apply a sequence model to a sequence model to make a brief outline of food descriptions. There are some issues with abstract text summarisation, like text process, vocabulary counting, missing word counting, word embedding, model potency or loss reduction, and smooth response engine summarisation. During this paper, the main goal was to extend the potency and scale back the losses from the sequence-to-sequence model to form a much better summary of abstract texts. This paper proposes four novel Sequence-to-Sequence (Seq2Seq) ATS models, using attention-based bidirectional long-short-term memory (LSTM), with further enhancements to extend the correlation between the generated outline text and also the supply text. and resolution of the matter of out-of-vocabulary (OOV) words, suppressing repeated words and preventing the propagation of additive errors in generated text summaries. Experiments conducted on 2 public datasets confirmed that the planned ATS models outperform the baseline and a few thought of progressive models.
SYSTEM:-
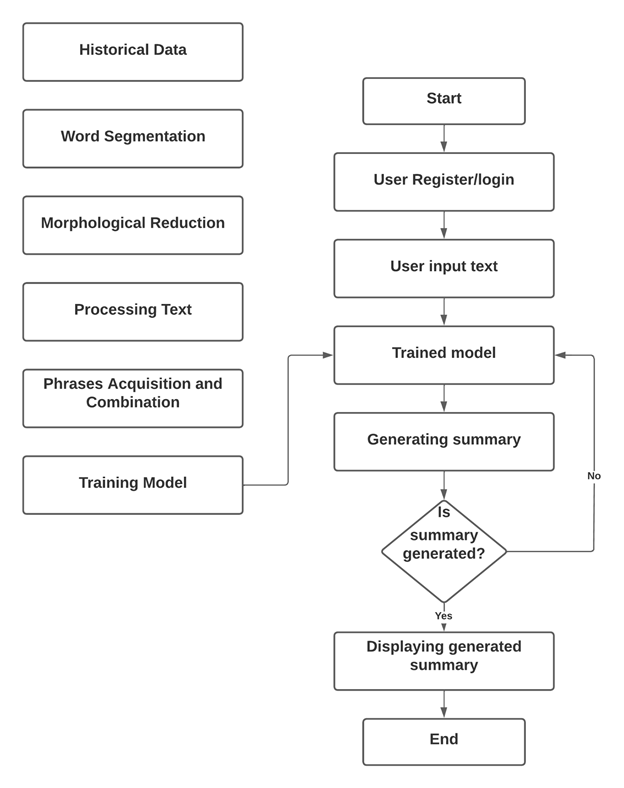
The goal of this system is to summarize a long text document into a shorter one while retaining the important information using LSTM and RNN models.
the system consists of the following modules:
- data preprocessing module: This module preprocesses the raw text data by removing stop words, punctuations, and converting the text into a numerical format that can be fed into the LSTM and RNN models.
- LSTM and RNN model module: This module contains the LSTM and RNN models that are used for text summarization. The LSTM and RNN models are trained on large datasets of text data to learn how to summarize text effectively.
- Evaluation module: This module evaluates the performance of the LSTM and RNN models by comparing the generated summaries with the actual summaries.
- Deployment module: This module deploys the trained LSTM and RNN models to summarize new text data.
the working of the system is as follows:
- The raw text data is preprocessed to remove stop words, punctuations, and convert it into a numerical format.
- The preprocessed data is fed into the LSTM and RNN models, which learn to summarize text effectively based on the input data.
- The performance of the LSTM and RNN models is evaluated using metrics like Rouge score, precision, and recall.
- The trained LSTM and RNN models are then deployed to summarize new text data in real-time.
The advantages of using LSTM and RNN models for abstractive text summarization include:
- They can capture the context of the text and generate more informative summaries.
- They can handle longer sequences of text and generate more coherent summaries.
- They can be trained on large datasets of text data to improve their summarization performance.
In conclusion, the Abstractive Text Summarization Using LSTM and RNN system is a powerful tool that can be used to automatically summarize long text documents into shorter, more informative summaries.
PROPOSED SYSTEM:-
In Automatic Text summarization, Singular input content is made by using unsupervised learning which will outline the profound rate of summarization. To find thescore of various sentences , the connection between each other is streamlined. All the sentences having the most weight are chosen. As per the rate of summarization various sentences are selected.
Step 1:
Data Preprocessing Programmed record outline generator helps in removing the things which are not required and occurs in substance. Hence there are sentence parts,empty stopwords and stemming.
Step 2:
Evaluation is further done by the weights Lesk count and word net is used to process the repeat of every sentence. For all N numbers of documents the total is spread and found between detail and brilliance. Further, a specific sentence of the document is selected for every sentence. From every sentence, the stop words are removed as there is no intrigue in the sense assignment process. Every word is removed with the help of Wordnet. The document is selected and performed between the sparkles and the data content. When it is overall the intersection guide comes to the largeness of the sentence.
Step 3:
Summarization is the last stage for automatic summarization. The last outline of the particular stage is evaluated, the introductions of the yield and survey is done at the time when all the sentences are arranged. Firstly, it will select the onceover of sentences with weight and are planned in jumping demand which is concerned by the increasing weights. Various numbers of sentences are picked from the rate of summary. Further the sentences which are picked are recomposed by the gathering of information. Further, the sentences which are selected are gathered without any dependence on any particular object rather than the denotative erudition lying in the sentence. Restrained matter once-over is without spoken language.
MODULES:-
- text preprocessing module: This module will be responsible for cleaning and preprocessing the input text data. It will include tasks such as tokenization, removing stop words, stemming or lemmatization, and removing special characters and punctuations.
- word embedding module: This module will convert the preprocessed text data into numerical vectors that can be processed by the neural network. It will use techniques such as Word2Vec or GloVe to create dense vector representations of words in the text.
- LSTM and RNN Module: This module will implement the LSTM and RNN models for abstractive text summarization. It will include layers such as embedding layer, LSTM layer, RNN layer, and output layer. The LSTM and RNN layers will learn the hidden representation of the input text and generate the summary.
- attention mechanism module: This module will be used to improve the performance of the LSTM and RNN models. It will include the attention mechanism, which helps the model to focus on important parts of the input text during the summarization process.
- Evaluation Module: This module will evaluate the performance of the model by computing metrics such as Rouge-N, which measures the similarity between the generated summary and the reference summary.
- user interface module: This module will provide an interface for the user to input the text data and view the generated summary. It can be a web application or a desktop application.
- Deployment Module: This module will be responsible for deploying the model into a production environment. It will include tasks such as model serialization, API development, and deployment on a cloud platform.
APPLICATION:-
- Input Text: The user can input the text that needs to be summarized. This can be done either by typing the text or by uploading a document containing the text.
- Preprocessing: The text is preprocessed to remove unnecessary elements such as stop words, punctuations, and special characters.
- LSTM and RNN Model: The preprocessed text is then passed through the LSTM and RNN model. This model analyzes the text and identifies the important keywords and phrases that summarize the text.
- Summary Generation: The important keywords and phrases identified by the model are then used to generate a summary of the input text. The summary is generated in a concise and coherent manner to ensure that it accurately represents the main idea of the text.
- Output: The summary is displayed to the user in a user-friendly interface. The user can then choose to save or share the summary.
- Feedback: The user can provide feedback on the summary generated by the system. This feedback can be used to improve the accuracy of the system in future iterations.
Overall, the application should be designed in a way that is intuitive and easy to use, with clear instructions for inputting the text, generating the summary, and providing feedback. The accuracy of the summary should be optimized through frequent updates to the LSTM and RNN model.
HARDWARE AND SOFTWARE REQUIREMENTS:-
HARDWARE:-
- Processor: Intel Core i3 or more.
- RAM: 4GB or more.
- Hard disk: 250 GB or more.
SOFTWARE:-
- Operating System : Windows 10, 7, 8.
- Python.
- Anaconda.
- Spyder, Jupyter notebook, Flask.
- MYSQL.