Visual question answering using probabilistic approach
ABSTRACT: –
Free-form and open-ended Visual Question Answering systems solve the problem of providing an accurate natural language answer to a question pertaining to an image. Current VQA systems do not evaluate if the posed question is relevant to the input image and hence provide nonsensical answers when posed with irrelevant questions to an image.A natural application of artificial intelligence is to help blind people overcome their daily visual challenges through AI-based assistive technologies. In this regard, one of the most promising tasks is Visual Question Answering (VQA): the model is presented with an image and a question about this image. It must then predict the correct answer. Recently has been introduced the VizWiz dataset, a collection of images and questions originating from blind people. Being the first VQA dataset deriving from a natural setting, VizWiz presents many limitations and peculiarities. More specifically, the characteristics observed are the high uncertainty of the answers, the conversational aspect of questions, the relatively small size of the datasets and ultimately, the imbalance between answerable and unanswerable classes. These characteristics could be observed, individually or jointly, in other VQA datasets, resulting in a burden when solving the VQA task. Particularly suitable to address these aspects of the data are data science pre-processing techniques. Therefore, to provide a solid contribution to the VQA task, we answered the research question “Can data science pre-processing techniques improve the VQA task? by proposing and studying the effects of four different pre-processing techniques. To address the high uncertainty of answers we employed a pre-processing step in which it is computed the uncertainty of each answer and used this measure to weight the soft scores of our model during training. The adoption of an “uncertainty-aware” training procedure boosted the predictive accuracy of our model providing a new state-of-the-art when evaluated on the test split of the dataset. In order to overcome the limited amount of data, we designed and tested a new pre-processing procedure able to augment the training set and almost double its data points by computing the cosine similarity between answers representation. We also addressed the conversational aspect of questions collected from real world verbal conversations by proposing an alternative question pre-processing pipeline in which conversational terms are removed. This led to a further improvement: from a predictive accuracy with the standard question processing pipeline, we were able to achieve predictive accuracy when employing the new pre-processing pipeline. Ultimately, we addressed the imbalance between answerable and unanswerable classes when predicting the answerability of a visual question. We tested two standard pre-processing techniques to adjust the dataset class distribution: oversampling and undersampling.
SYSTEM:-
- image processing module :This module will preprocess the input image by extracting visual features using techniques such as convolutional neural networks. cnns The visual features can capture important information about the objects and their relationships in the image
- text processing module: This module will preprocess the input question by converting it to a vector representation using techniques such as word embeddings. The vector representation can capture the meaning of the question in a more structured and computationally efficient way. probabilistic :reasoning module This module will use probabilistic models such as Bayesian networks or Markov random fields to reason about the joint probability distribution of the visual features and the question representation. The probabilistic model can incorporate prior knowledge and uncertainty into the prediction process.
- inference module: This module will use probabilistic inference algorithms such as belief propagation or Gibbs sampling to compute the posterior probability distribution of the answer given the visual features and the question representation. The inference process can involve message passing between the nodes of the probabilistic model.
- answer generation module: This module will generate the answer based on the posterior probability distribution computed by the inference module. The answer can be the most probable answer or a set of candidate answers with their corresponding probabilities.
- user interface module: This module will provide a user-friendly interface for users to input questions and images and receive the corresponding answers. The interface can be in the form of a web application or a mobile application
- evaluation module: This module will evaluate the performance of the VQA system using metrics such as accuracy, precision, recall, and f1 score. The evaluation can involve using a dataset of labeled images and questions with their corresponding answers.
The VQAanswers. system, using a probabilistic approach, can answer a wide range of questions about the content of images, including object recognition, scene understanding, and reasoning about relationships between objects. By combining visual and textual information in a probabilistic framework, the system can provide more accurate and robust answers even in the presence of uncertainty and ambiguity in the input.
PROPOSED SYSTEM:-
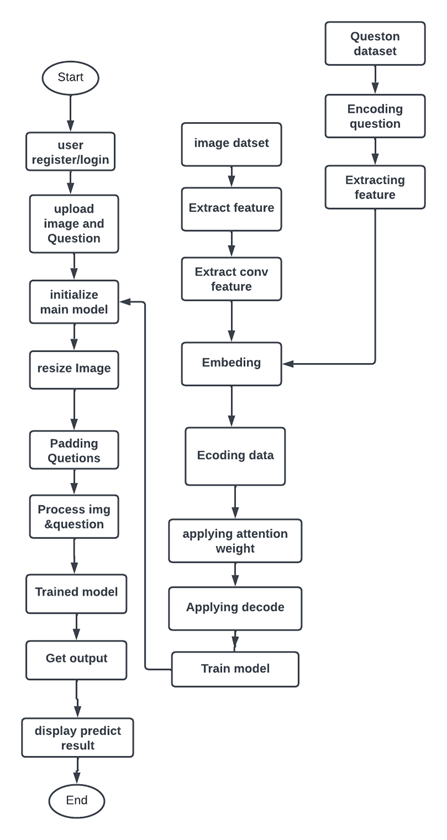
There are totally different strategies within the language+vision domain to seek out the solution to the question supported by the input image. However, each of the methodologies has their own pros and cons to figure effectively with the planned framework associated with nursing when a thoroughgoing comprehension of the given writing review seems to be an affordable and acceptable way to accomplish the best at school accuracy. We propose the Visual Question Answering system. Here we import the neural network to create a convolutional network layer for a particular image and extract the required image features. SpaCy word embeddings are used as a part of RNN for natural language processing to convert the question into a word vector, understanding its semantics.
The following steps are proposed
1) The primary step is going to be the word transformation for the question. We are going to convert every word to its word vector, and for that we are going to use the unconventional word embedding model.
2) Returning to the image is sent through a deep convolutional neural network from the well-known architecture, and therefore the image options are extracted from the activation of the second last layer, that is the layer before the soft max function .
3) To mix the options from the image and therefore the word vector, we tend to use a multilayer perceptron consisting of absolutely connected layers The layers are mentioned within the article. We get a probability distribution over all the potential outputs. The output with the very best likelihood is our answer to the question, which supported the image.
MODULES:-
- image processing module: This module will be responsible for preprocessing the input image by extracting visual features. It will utilize a convolutional neural network (CNN) to extract features from the image, such as object detection, scene recognition, and image segmentation.
- text processing module: This module will preprocess the input question by converting it to a vector representation using techniques such as word embeddings. The vector representation can capture the meaning of the question in a more structured and computationally efficient way. probabilistic reasoning module: This module will be responsible for reasoning about the joint probability distribution of the visual features and the question representation. It will use probabilistic models such as Bayesian networks or Markov random fields to incorporate prior knowledge and uncertainty into the prediction process.
- inference module This module will use probabilistic inference algorithms such as belief propagation or Gibbs sampling to compute the posterior probability distribution of the answer given the visual features and the question representation. The inference process can involve message passing between the nodes of the probabilistic model
- answer generation module. This module will be responsible for generating the answer based on the posterior probability distribution computed by the inference module. The answer can be the most probable answer or a set of candidate answers with their corresponding probabilities.
- user interface module: This module will provide a user-friendly interface for users to input questions and images and receive the corresponding answers. The interface can be in the form of a web application or a mobile application
- evaluation module: This module will be responsible for evaluating the performance of the VQA system using metrics such as accuracy, precision, recall, and f1 score. The evaluation can involve using a dataset of labeled images and questions with their corresponding answers.
Each of these modules will work together to provide a seamless and efficient visual question-answering system using a probabilistic approach. By combining the power of visual and textual data, this system can answer a wide range of questions related to the content of images.
APPLICATION:-
- user interface :The user interface would allow users to upload an image and type in a question related to the content of the image. The interface would be designed to be user-friendly and intuitive, with features such as autocomplete and suggestions to help users form their questions.
- image processing: the application would utilize a pre-trained convolutional neural network (CNN) to extract features from the image, such as object detection, scene recognition, and image segmentation. These features would be used to represent the visual content of the image
- text processing: The application would preprocess the user’s question by converting it to a vector representation using techniques such as word embeddings. The vector representation would capture the meaning of the question in a more structured and computationally efficient way.
- probabilistic reasoning :The application would use a probabilistic model such as a Bayesian network or Markov random field to reason about the joint probability distribution of the visual features and the question representation. This would allow the application to incorporate prior knowledge and uncertainty into the prediction process.
- Inference: The application would use probabilistic inference algorithms such as belief propagation or Gibbs sampling to compute the posterior probability distribution of the answer given the visual features and the question representation. The inference process would involve message passing between the nodes of the probabilistic model
- answer generation: The application would generate an answer based on the posterior probability distribution computed by the inference module. The answer could be the most probable answer or a set of candidate answers with their corresponding probabilities.
- Output: The application would present the user with the answer to their question. The output could be in the form of text, a spoken response, or a combination of both.
The VQA application would allow users to ask a wide range of questions related to the content of an image, such as what animal is in the picture or what the color of the car in the image is. The use of a probabilistic approach would ensure that the application is able to provide accurate and robust answers even in the presence of uncertainty and ambiguity in the input.
HARDWARE AND SOFTWARE REQUIREMENTS:-
HARDWARE:-
Processor: Intel Core i3 or more.
• RAM: 4GB or more.
• Hard disk: 250 GB or more.
SOFTWARE:-
- Operating System : Windows 10, 7, 8.
- Python
- anaconda
- Spyder, Jupyter notebook, Flask.
- MYSQL