SIGN LANGUAGE TO TEXT AND SPEECH CONVERSION
ABSTRACT:-
Sign language is one of the oldest and maximum natural forms of language for communication. Since maximum human beings now no longer know signal language and interpreters are very hard to return back by, we’ve provided you with a real-time technique the usage of Convolution Neural Network (CNN) for fingerspelling primarily based totally on American Sign Language (ASL). In our technique, the hand is first exceeded via a filter and after the filter has implemented the hand is passed via a classifier that predicts the elegance of the hand gestures.
OBJECTIVES OF THE PROJECT:
FOR SIGN TO SPEECH CONVERSION
- Acquire images using the inbuilt camera of the device.
- Perform vision analysis functions in the open thing system and provide speech output through the inbuilt audio device.
FOR SPEECH TO SIGN CONVERSION
- Acquire speech input using the inbuilt microphone of the device.
- Perform speech analysis functions in the open thing system and provide visual sign output through the inbuilt display device.
MINIMIZE HARDWARE REQUIREMENTS AND EXPENSES
EXISTING SYSTEM
SIGN LANGUAGE RECOGNITION SYSTEM.
Sign language popularity is a vital software of gesture popularity. Sign language popularity has distinct processes.
– Glove based approaches
– Vision based approaches.
GLOVE BASED APPROACHES
This class calls for signers to put on a sensor glove or a coloured glove. The challenge could be simplified throughout the segmentation procedure via the means of wearing gloves. The disadvantage of this technique is that the signer has to put on the sensor hardware together with the glove throughout the operation of the system.
VISION BASED APPROACHES
Image processing algorithms are utilized in Vision primarily based totally on the approach to locate and tune hand symptoms and symptoms and facial expressions of the signer. This approach is less complicated to the signer for the reason that there isn’t any any want to put on any more hardware. However, there are accuracy issues associated with photograph processing algorithms and those issues are but to be modified.
There are once more distinct processes in imaginative and prescient primarily based totally sign language popularity:
-3-D model based
-Appearance based
3-D version primarily based totally techniques employ 3-D statistics of key factors of the frame components. Using this statistics, several vital parameters, like palm position, joint angles etc., can be obtained. This technique makes use of volumetric or skeletal models, or an aggregate of the . Volumetric technique is higher acceptable for pc animation enterprise and pc imaginative and prescient. This technique may be very computational extensive and also, structures for stay evaluation are nonetheless to be developed. Appearance-primarily based total structures use pix as inputs. They at once interpret from those movies/pix. They don’t use a spatial illustration of the frame. The parameters are derived at once from the pix or movies the use of a template database. Some templates are the deformable 2D templates of the human components of the frame, mainly hands. The units of points at the define of an item referred to as deformable templates. It is used as interpolation nodes for the items defining approximation.
PROPOSED SYSTEM
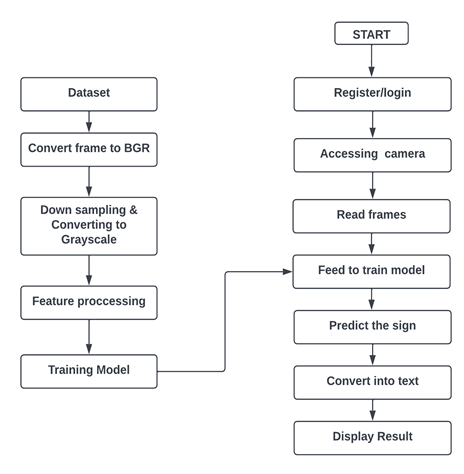
IMAGE CAPTURING FROM CAMERA:
The net digital digicam is used to capture the motions. The complete signing length is captured using this OpenCV video flow. Frames from the flow are retrieved and transformed to grayscale images.
HAND GESTURE SCAN:
Hand motions are scanned withinside the accrued images. This is a step withinside the preprocessing process that happens earlier than the photograph is fed into the version for prediction. The passages which include gestures have been amplified. This multiplies the chance of an accurate forecast through an element of ten.
HAND POSTURE RECOGNITION:
The Keras CNN version is fed the preprocessed pictures. The projected label is generated with the aid of using the version that has already been trained. All of the gesture labels have a chance related to them. The anticipated label is decided with the aid of using the label with the very best likelihood.
GESTURE CLASSIFICATION:
to expect the very last image of the user quite a few symbols that offer comparable effects are detected, the classifiers designed specially for the ones units to categorize among them are used.
TEXT AND SPEECH TRANSLATION:
The version translates recognised gestures into phrases the gtts library is used to convert the identified words into the precise speech the text-to-speech output is a easy workaround however it is a useful function as it simulates a real-life dialogue.
ADVANTAGES :
- American Sign Language is a language that can be seen. Along with signing, the ideas use vision to process language data
- Sign language isn’t a typical language – it’s used by every single person in the United States.
- The model translates known gestures into words. The GTTS library is used to convert the recognized words into the appropriate speech.
HARDWARE AND SOFTWARE REQUIREMENTS:-
HARDWARE:-
- Processor: Intel Core i3 or more.
- RAM: 4GB or more.
- Hard disk: 250 GB or more.
SOFTWARE:
- Operating System : Windows 10, 7, 8.
- Python
- Anaconda
- Spyder, Jupyter notebook, Flask.