AI VOICE ASSISTANCE
ABSTRACT: –
Artificial intelligence era is starting to be actively utilized in human life, making it simpler to visualize. Independent gadgets are clever in their methods of speaking with each other. One of the maximum suitable sorts of synthetic intelligence is the capacity to realize human herbal language. New thoughts in this text may also result in new methods of operating with the human system, wherein the system will learn how to understand, adapt, and have interaction with it. Thus, we want to broaden a private assistant having splendid powers of deduction and the capacity to have interaction with the environment simply with the aid of using one of the materialistic styles of human interaction, i.e., with the aid of using voice.
Desktop-primarily based totally voice assistants are applications which can realize human voices and might reply through an incorporated voice system. To convert textual content to audio, we are able to use APIs. We use the synthetic intelligence era for this project. Use Python as a programming language as well, as it has a big library. This software program makes use of a microphone as an enter tool to get hold of voice requests from the consumer and a speaker as an output tool to present the output voice.
SYSTEM:-
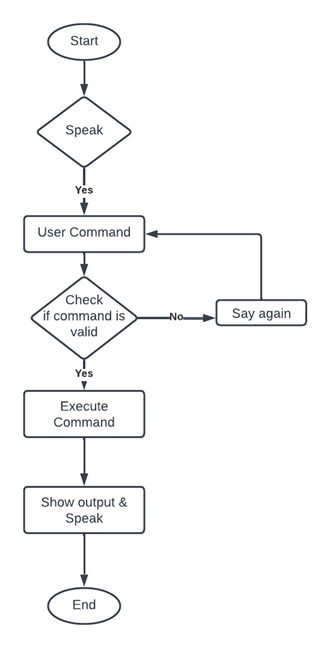
- Audio Input: The system begins with an audio input module that captures the user’s voice commands. The module may use a microphone or other audio capture device to record the user’s voice.
- Speech Recognition: The audio input is then processed by a speech recognition module that converts the spoken words into text. This module uses algorithms such as Hidden Markov Models (HMMs) or Deep Neural Networks (DNNs) to recognize and transcribe the user’s speech.
- Natural Language Processing: The transcribed text is then processed by a natural language processing (NLP) module that analyzes the meaning of the user’s commands. The NLP module uses techniques such as part-of-speech tagging, parsing, and semantic analysis to understand the intent behind the user’s words.
- Dialogue Management: Once the user’s intent has been identified, a dialogue management module generates a response to the user’s command. This module may use rule-based or machine learning-based approaches to generate appropriate responses. For example, if the user asks for the weather, the dialogue management module may query a weather API and generate a response such as “Today’s forecast is sunny with a high of 75 degrees.”
- Text-to-Speech Conversion: The response generated by the dialogue management module is then passed to a text-to-speech (TTS) conversion module that converts the response into an audio signal. This module may use techniques such as concatenative synthesis or parametric synthesis to generate natural-sounding speech.
- Audio Output: Finally, the audio signal is output through a speaker or other audio output device to deliver the response to the user.
- The above steps can be repeated for each user command or query, allowing the voice assistance system to provide a seamless and intuitive user experience. Additionally, the system can be designed to learn from user interactions, allowing it to adapt and improve over time.
PROPOSED SYSTEM:-
The proposed system will provide the following features:
1) It always keeps listening and wakes up to respond with the assigned functionality when called.
2) It keeps learning the sequence of questions asked of it related to its context, which it remembers for the future. So when the same context is mentioned again, it starts a conversation with you asking relevant questions.
3) carrying out arithmetic calculations based on voice commands and returning the computed solution via voice.
4) Searching the Internet based on a user’s voice input and giving back the reply through a voice with further interactive questions by machine.
5) The data will keep auto synchronization updated.
6) Other features such as playing music, setting an alarm, checking weather conditions at the device’s location Setting reminders, spell-checking, and other functions can be performed using voice input.
MODULES:-
- Audio Input Module: This module is responsible for capturing the user’s voice commands. It may use a microphone or other audio capture device to record the user’s voice.
- Speech Recognition Module: The audio input is then processed by a speech recognition module that converts the spoken words into text. This module uses algorithms such as Hidden Markov Models (HMMs) or Deep Neural Networks (DNNs) to recognize and transcribe the user’s speech.
- Natural Language Processing Module: The transcribed text is then processed by a natural language processing (NLP) module that analyzes the meaning of the user’s commands. The NLP module uses techniques such as part-of-speech tagging, parsing, and semantic analysis to understand the intent behind the user’s words.
- Dialogue Management Module: Once the user’s intent has been identified, a dialogue management module generates a response to the user’s command. This module may use rule-based or machine learning-based approaches to generate appropriate responses. For example, if the user asks for the weather, the dialogue management module may query a weather API and generate a response such as “Today’s forecast is sunny with a high of 75 degrees.”
- Text-to-Speech Conversion Module: The response generated by the dialogue management module is then passed to a text-to-speech (TTS) conversion module that converts the response into an audio signal. This module may use techniques such as concatenative synthesis or parametric synthesis to generate natural-sounding speech.
- Audio Output Module: Finally, the audio signal is output through a speaker or other audio output device to deliver the response to the user.
- The above modules can be implemented using various programming languages and tools, depending on the specific requirements and constraints of the project. Additionally, the modules can be further optimized and customized to improve the accuracy and efficiency of the voice assistance system.
APPLICATION:-
- Wake Word Detection: The application is always listening for a specific wake word, such as “Hey Assistant”. When the wake word is detected, the application activates and starts processing the user’s command.
- Command Recognition: The application uses a speech recognition module to transcribe the user’s spoken command into text. This text is then processed by a natural language processing module to understand the user’s intent and extract relevant information.
- Response Generation: Based on the user’s command and intent, the application generates a response using a dialogue management module. The response may include information such as the weather, news, or calendar events, or perform an action such as setting a reminder or sending a message.
- Audio Output: The response generated by the application is converted into an audio signal using a text-to-speech conversion module, and output through the device’s speakers.
- Additional Features: The application may also include additional features such as personalized settings, integration with third-party services, or voice biometrics for improved security.
HARDWARE AND SOFTWARE REQUIREMENTS:-
HARDWARE:-
- Processor: Intel Core i3 or more.
- RAM: 4GB or more.
- Hard disk: 250 GB or more.
- Web camera
SOFTWARE:-
- Operating System : Windows 10, 7, 8.
- python
- anaconda
- Spyder, Jupyter notebook, Flask.
- MYSQL