Speech Emotion Recognition
ABSTRACT: –
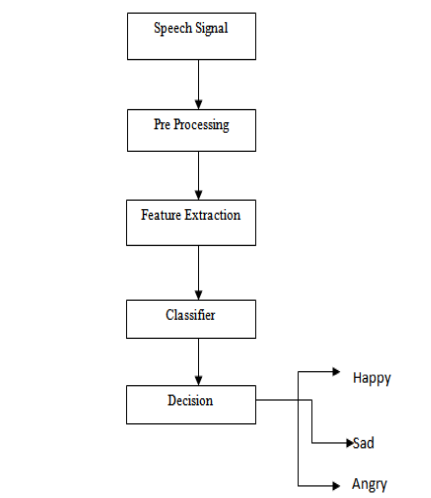
Emotions play a very important role in a person’s mental life. It is a means of expressing one’s point of view or psychological state to others. Speech emotion recognition is defined as extracting the speaker’s emotion from the speaker’s speech signal. There are several universal emotions, including neutrality, anger, happiness, and frustration, during which intelligent systems with finite procedural resources learn to identify or synthesize them as needed. In this task, spectra and staging options are used to recognise speech sensations because each option contains emotion data. Mel-frequency cepstral coefficients (MFCC) are one spectral option. Fundamentals of speech: volume, pitch, and strength; parameters of speech organs; transmission parameters used to simulate completely different emotions. Potential variants are extracted from each vocalization for matching procedures with emotion and speech patterns. The stage is revealed in the selected option, and the sacrifices of this gender are classified. Deep learning techniques such as VGG16, VGG16, VGG19, AlexNet, and InceptionV3 are used to classify gender during this task. Radial bases operate, and the back propagation network is used to recognise the emotions supported by the chosen options. It has been established that radial bases operate and turn out additional correct results for emotion recognition than the back propagation network. Speech emotion recognition is the act of predicting a human’s emotion through their speech, along with the accuracy of the prediction. It creates a better human-computer interaction. Though it is difficult to predict the emotion of a person as emotions are subjective and annotating audio is challenging, “Speech Emotion Recognition (SER)” makes this possible. This is the same theory that is used by animals like dogs, elephants, horses, etc. to be able to understand human emotion.
SYSTEM:-
Speech Emotion Recognition (SER) using Artificial Intelligence (AI) involves the use of advanced algorithms that can analyze speech signals and detect the emotional state of the speaker. Here’s an overview of a SER system using AI:
- Data Collection: Collect a large dataset of speech samples that includes different emotional states such as anger, happiness, sadness, fear, and neutral. The dataset should include diverse speakers and a range of speaking styles to make the model more robust.
- Data Preprocessing: Preprocess the collected data by segmenting the speech samples into smaller frames and extracting relevant features such as pitch, energy, and spectral features. This step may also include noise reduction and normalization.
- Feature Extraction: Extract features from the preprocessed speech data using techniques such as Mel Frequency Cepstral Coefficients (MFCCs), Linear Predictive Coding (LPC), and Prosodic features. These features capture the underlying acoustic characteristics of the speech signal that are associated with different emotional states.
- Artificial Intelligence Model Training: Train an AI model, such as a Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), or Long Short-Term Memory (LSTM) network, on the extracted features. The model should learn to differentiate between the different emotional states based on the input speech features.
- Model Evaluation: Evaluate the trained model’s performance by testing it on a separate dataset that includes speech samples with different emotional states. The model’s accuracy, precision, recall, and F1-score should be evaluated to assess its performance.
- Real-time Emotion Detection: Use the trained AI model to detect the emotional state of a speaker in real-time. This involves continuously analyzing the incoming speech signal and classifying it into one of the emotional states.
- Application Integration: Integrate the SER system into an application, such as a virtual assistant or call center software. The system can be used to provide better customer service by detecting the emotional state of the speaker and adjusting the response accordingly.
Overall, a SER system using AI can be a powerful tool for understanding the emotional state of speakers in various applications. It can improve customer service, enhance communication, and help to build better relationships between people.
PROPOSED SYSTEM:-
1) It always keeps listening and wakes up to respond with the assigned functionality when called.
2) It keeps learning the sequence of questions asked of it related to its context, which it remembers for the future. So when the same context is mentioned again, it starts a conversation with you asking relevant questions.
3) carrying out arithmetic calculations based on voice commands and returning the computed solution via voice.
4) Searching the Internet based on a user’s voice input and giving back the reply through a voice with further interactive questions by machine.
5) The data will keep auto synchronization updated.
6) Other features such as playing music, setting an alarm, checking weather conditions at the device’s location Setting reminders, spell-checking, and other functions can be performed using voice input.
MODULES:-
- data collection module: this module is used to collect a large dataset of speech samples that includes different emotional states such as anger happiness sadness fear and neutral. the dataset should include diverse speakers and a range of speaking styles to make the model more robust data preprocessing module: this module is used to preprocess the collected data by segmenting the speech samples into smaller frames and extracting relevant features such as pitch energy and spectral features this step may also include noise reduction and normalization.
- feature extraction module: this module is used to extract features from the preprocessed speech data using techniques such as mel frequency cepstral coefficients mfccs linear predictive coding lpc and prosodic features these features capture the underlying acoustic characteristics of the speech signal that are associated with different emotional states.
- artificial intelligence model training module: this module is used to train an ai model such as a convolutional neural network cnn recurrent neural network rnn or long short-term memory lstm network on the extracted features the model should learn to differentiate between the different emotional states based on the input speech features .
- model evaluation module: this module is used to evaluate the trained models performance by testing it on a separate dataset that includes speech samples with different emotional states the module should compute the models accuracy precision recall and f1-score to assess its performance. real-time emotion detection module: this module is used to use the trained ai model to detect the emotional state of a speaker in real-time this involves continuously analyzing the incoming speech signal and classifying it into one of the emotional states.
- application integration module: this module is used to integrate the ser system into an application such as a virtual assistant or call center software the system can be used to provide better customer service by detecting the emotional state of the speaker and adjusting the response accordingly
APPLICATION:-
- customer service: SER can be used in call centers and other customer service applications to detect the emotional state of the customer and adjust the response accordingly for example if a customer is angry the system can route the call to a supervisor or provide an apology to defuse the situation .
- mental health: services can be used to monitor the emotional state of patients with mental health conditions such as depression or anxiety this information can be used by therapists and doctors to track the patients progress and adjust treatment accordingly .
- education: SER can be used to detect the emotional state of students during online classes or exams this information can be used by teachers to adjust their teaching style and provide support to students who are struggling.
- Entertainment : SER can be used in the entertainment industry to create more immersive and interactive experiences for example a video game could use a sensor to detect the emotional state of the player and adjust the games difficulty or storyline accordingly.
- Marketing: SER can be used to gauge the emotional response of customers to advertisements and other marketing materials this information can be used to refine marketing strategies and create more effective campaigns.
HARDWARE AND SOFTWARE REQUIREMENTS:-
HARDWARE:-
- Processor: Intel Core i3 or more.
- RAM: 4GB or more.
- Hard disk: 250 GB or more.
SOFTWARE:-
- Operating System : Windows 10, 7, 8.
- Python
- Anaconda
- Spyder, Jupyter notebook, Flask.